
Everyone who is familiar with software technology trends within past few years has surely met with the concepts of machine and deep learning as well as artificial intelligence, whether in articles or other contexts. It seems nowadays these terms are also widely used even while marketing different software solutions.
The FrostBit Software Laboratory has also studied some of the ways of machine and deep learning in recent times. Our laboratory is especially interested in the wide array of possibilities of these new technologies; what are the software features they allow us to create more easily which are either extremely difficult or even outright impossible to engineer?
From the technological point of view, most machine learning related applications are created by using the Python language. The reason for this is the fact, that Python offers a stunning selection of different tools and libraries that are especially crafted for machine learning applications and cases.
The basic concept of machine learning is the following: We provide our machine learning application the data, which is used to create desired predictions for new data. The data will be split into two parts: the training data and the testing data. The training data is used to teach the machine learning algorithm to understand all the features of the data as well as the complex correlations that lie within. The test data is used later on to make sure the algorithm is capable of creating predictions within the limits of acceptable error margins.
Machine learning can be utilized in many applications. Some traditional use cases:
- supporting decision-making based on earlier decisions
- determining the market value based on sales history (e.g. real estate prices)
- natural language processing (e.g. spam e-mail detection)
- finding complex correlations in given data (e.g. what are the features of a typical web store customer during a certain ad campaign)
- recommender systems (e.g. web store product recommendation features)
- data classification (e.g.. determining whether a tumor is benign or malign based on earlier measurements)
- etc.
Deep learning is a subcategory of machine learning. The basic difference between the two concepts lie within the way they strive to create predictions based on the given data. While the traditional machine learning algorithms aim to create their predictions based on a single operation, deep learning algorithms utilize so-called neural networks while creating predictions. Neural networks are collections of layers and nodes, through which the training data is processed for the learning model. The finalized learning model will be used to create predictions when given new data. Since the training phase is distributed among multiple layers and nodes, it will create a certain amount of natural chaos or humanity in the data processing phase.
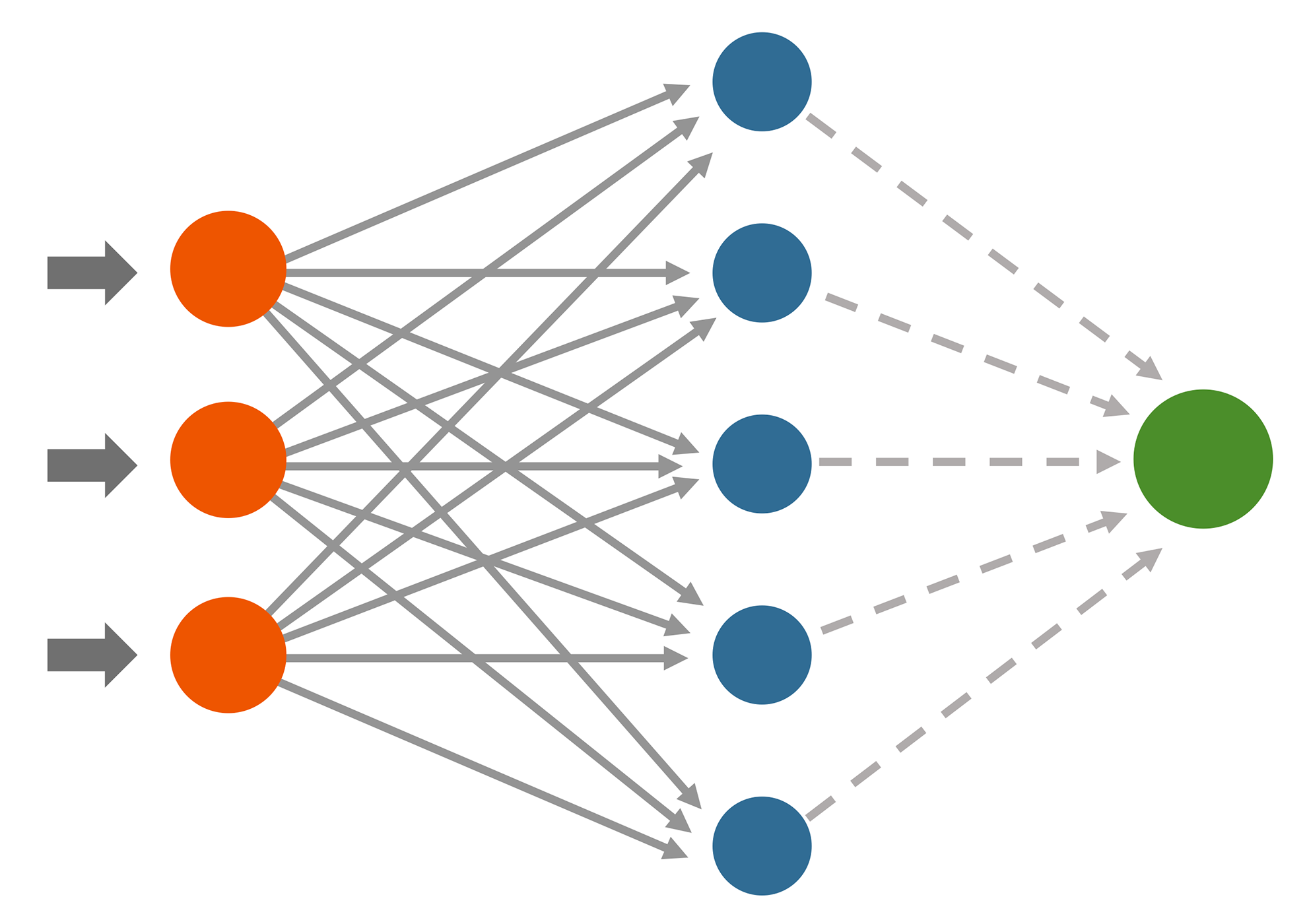
Because of this, the deep learning process is a much more organic way to create new predictions when compared to traditional machine learning methods. The organic feature of deep learning also means, that it is virtually impossible to get the same exact results every time, even while using the exact same data and chosen algorithm in the training phase.
The possibilities of machine and deep learning are amazing, but as often in trending technologies, the realistic use cases are often forgotten. Too often there are discussions, where machine and deep learning are regarded as all-solving silver bullets, which can solve any given IT problem easily. The truth, however, is much more closer to the concept, that machine and deep learning are actually just extremely demanding tools, that potentially can provide useful information for challenging problems. How well machine and deep learning algorithms work in practice, is always dependant on the context and especially on the fact, how much time and willpower the software developers and context experts can possibly provide.
The quality of the training data also plays a significant role in machine learning. If there is not enough data or it is not versatile or relevant enough, the predictions based on the data are most likely not usable. Machine and deep learning require a lot of time and effort, and it also resembles both statistics and quantitative research analysis at the same time. From the software developer’s point of view, the challenge is to find the correct analysis method for the correct problem, while the data is processed in the correct way.
Machine learning also requires the developer to spend a great deal of time to explore the data and create personal decisions, which features of the data are relevant and which are not. All irrelevant data will undermine the precision of the machine learning application predictions. As an additional challenge, machine learning contains a vast amount of theory, that has to be utilized while developing a machine learning application. However, the actual programming phase is not that difficult in machine learning applications. Instead, deciding which methods to use and in which way is the actual challenge. Because of this, the machine learning application software developers always need to be accompanied with experts of the context of the data as well as experts on different research and analysis methods.
We are eager to work more with all these technologies in future projects!