
Jokainen, joka on seurannut ohjelmistotekniikan trendejä viimeisten vuosien aikana, on taatusti törmännyt kone- ja syväoppimisen käsitteisiin eri artikkeleissa ja asiayhteyksissä. Jopa teknologisten tuotteiden mainostamisessa hyödynnetään kone- ja syväoppimiseen sekä tekoälyyn liittyviä termejä.
Myös FrostBit –laboratorio on perehtynyt kone – ja syväoppimisen saloihin viime aikoina. Erityisesti koneoppimisessa meitä kiinnostaa sen mahdollisuudet eri käyttötapauksissa; mitä kaikkea sillä voidaan saavuttaa uusissa sovelluksissa jotka muutoin ovat joko erittäin vaikeita tai jopa mahdottomia toteuttaa?
Teknologisesta näkökulmasta tänä päivänä lähes kaikki koneoppimiseen liittyvät sovellukset luodaan Python –ohjelmointikielellä. Tämä johtuu siitä, että Pythonille on saatavilla runsaasti erilaisia aputyökaluja ja kirjastoja, jotka on nimenomaan rakennettu koneoppimisen tarpeisiin.
Pähkinänkuoressa koneoppiminen toimii siten, että ohjelmalle syötetään tarkasteltava data, jonka pohjalta tehdään haluttuja päätelmiä. Data jaetaan kahteen osaan: opetusdataan ja testausdataan. Opetusdatan avulla valittu koneoppimisalgoritmi opetetaan ymmärtämään kaikki se, mistä osista valittu data koostuu ja mitkä asiat liittyvät tai korreloivat toisiinsa. Testidatan avulla testataan lopuksi, kuinka hyvin algoritmi kykenee syötetyn datan pohjalta tekemään päätelmiä sovitun virhemarginaalin puitteissa.
Koneoppimista voidaan hyödyntää useissa eri sovelluksissa. Joitain perinteisiä käyttötapauksia:
- päätöksenteon tukeminen aiempien päätösten pohjalta
- markkina-arvon päätteleminen historiatietojen perusteella (esim. asuntojen hinnat)
- luonnollisen kielen prosessointi (esim. roskapostin tunnistaminen)
- monimutkaisten korrelaatioiden etsiminen tietoaineistosta (esim. millainen on tyypillinen verkkokaupan asiakas tietyn mainoskampanjan aikana)
- suositusjärjestelmät (esim. verkkokauppojen tuotesuositusominaisuudet)
- tiedon luokittelu (esim. onko syöpäkasvain hyvä- vai pahalaatuinen historiatiedon pohjalta)
- jne.
Syväoppiminen on koneoppimisen alakategoria, jonka suurin ero tavanomaiseen koneoppimiseen on siinä, miten se pyrkii ennakoimaan uutta tietoa aiemman tiedon perusteella. Kun koneoppimisen algoritmit pyrkivät tekemään päätelmänsä yksittäisen operaation pohjalta, syväoppiminen hyödyntää sen sijaan neuroverkkoja päätelmien tekemisessä. Neuroverkot ovat kokoelma tasoja ja yhdyspisteitä, joiden kautta opetettava data käsitellään opetusmallia varten. Neuroverkkojen avulla syväoppimisen algoritmit rakentavat alkuperäisen datan pohjalta opetusmallin, jonka pohjalta uusia päätelmiä uudesta datasta voidaan tehdä. Koska tiedon oppiminen on jaettu useisiin tasoihin ja yhdyspisteisiin, tuo se tietyn määrän luonnollista kaaosta tai ihmisyyttä datan käsittelyyn.
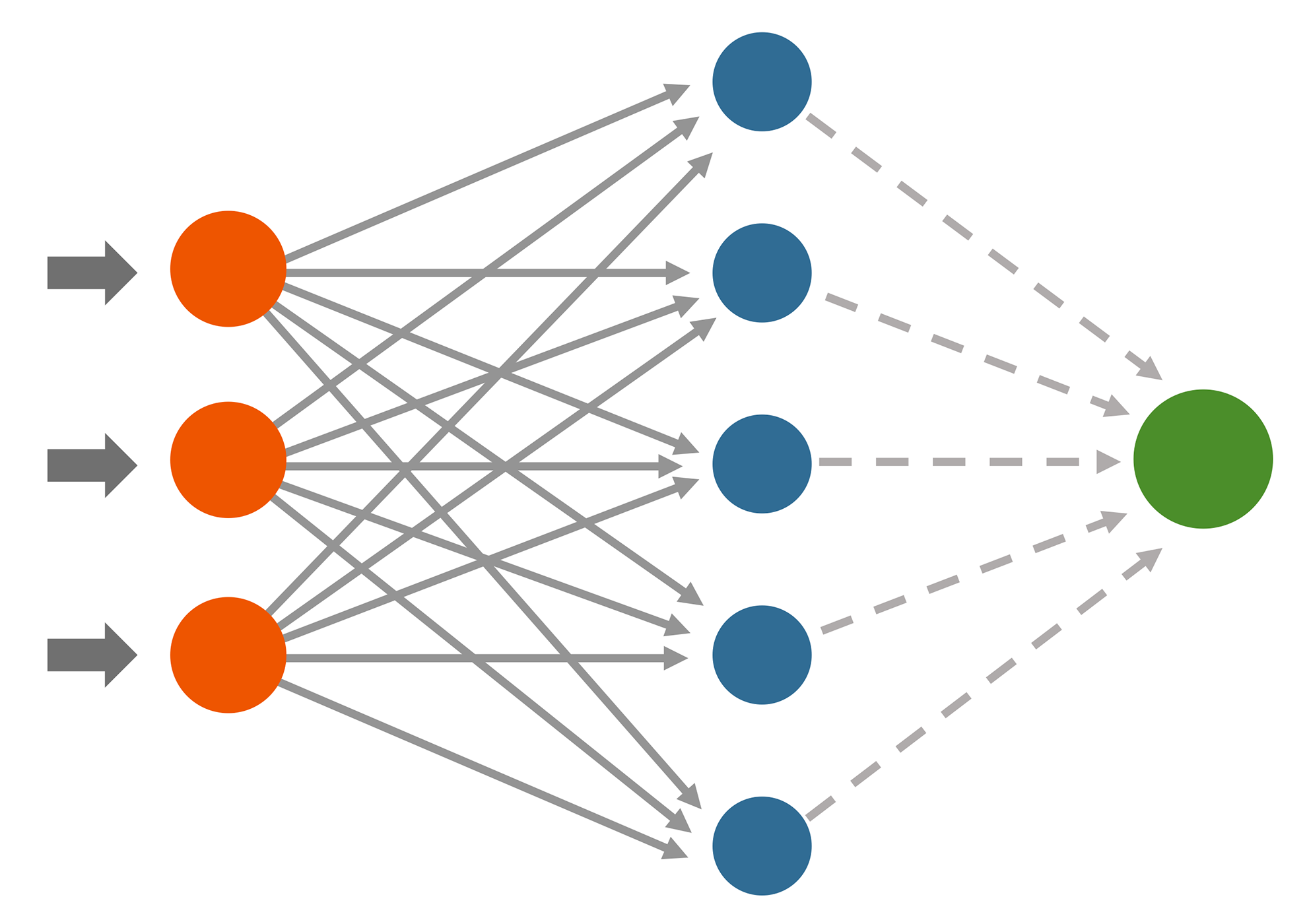
Tämän vuoksi syväoppimisen prosessi on huomattavasti orgaanisempi tapa ennakoida tietoa kuin perinteiset koneoppimisen menetelmät. Tämä orgaanisuus tarkoittaa samalla myös sitä, että täysin identtisiin lopputuloksiin syväoppimisen menetelmillä ei koskaan päästä, vaikka data ja valittu algoritmi olisi joka kerta täysin sama.
Kone- ja syväoppimisen mahdollisuudet ovat valtavat, mutta kuten usein trendikkäissä teknologioissa, kovin helposti unohdetaan niiden realistiset käyttökohteet. Liian usein tulee vastaan keskusteluja, joissa kone- ja syväoppimista pidetään ylivoimaisena ratkaisuna kaikkiin mahdollisiin haasteisiin, joihin tietotekniikka millään tavalla liittyy. Totuus on kuitenkin lähempänä sitä, että kone- ja syväoppiminen on enemmänkin kehittäjältään paljon vaativa työkalu, jolla voidaan potentiaalisesti saada hyödyllistä tietoa haastaviin ongelmiin. Se, kuinka hyvin kone- ja syväoppimisen algoritmit toimivat käytännössä, riippuu aina kontekstista ja erityisen paljon siitä, kuinka paljon vaivaa ohjelmoijat ja heidän tukenaan toimivat kontekstiasiantuntijat näkevät.
Erityisen suuri merkitys koneoppimisessa on myös opetusdatan laadulla. Jos dataa ei ole tarpeeksi tai se ole tarpeeksi monipuolista ja relevanttia, tulevat sen pohjalta tehdyt päätelmät todennäköisesti olemaan virheellisiä. Kone- ja syväoppiminen vaatii paljon aikaa ja vaivaa, ja monilta osin se muistuttaa tilastomatematiikan lisäksi myös määrällistä tutkimusta. Useat kone- ja syväoppimisen analysointimenetelmät ovat samankaltaisia määrällisen tutkimuksen analyysimenetelmien kanssa. Haaste onkin siinä, että sovelluksen kehittäjä osaa valita oikeaan ongelman oikean menetelmän samalla, kun dataa käsitellään oikealla tavalla.
Koneoppimisessa menee paljon aikaa myös datan tutkimiseen ja päätelmien tekemiseen siitä, mikä tieto on tärkeää ja mikä ei. Kaikki ylimääräinen epäolennainen tieto heikentää koneoppimisen tarkkuutta. Lisähaasteena koneoppimisessa on myös siihen liittyvä kaikki teoria, jota täytyy hyödyntää koneoppimisen ohjelmoimisessa. Varsinainen ohjelmointi koneoppimistapauksissa ei ole ohjelmistosuunnittelijan näkökulmasta vaikeaa, vaan haaste on siinä, mitä menetelmää pitäisi käyttää ja millä tavalla. Tämän vuoksi koneoppimissovelluksen ohjelmoiminen vaatii tuekseen myös niitä, jotka tuntevat tutkittavan aineiston kontekstin sekä niitä, jotka ovat eri tutkimus- ja analyysimenetelmien asiantuntijoita.
Odotamme innolla, että pääsemme tekemään kaikkea tätä lisää käytännön projekteissa!