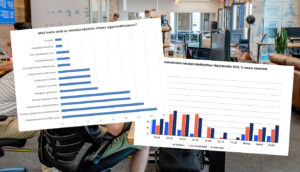
Adoption of Artificial Intelligence and Workplace Equality – Insights from the KITT Project
In 2025, generative artificial intelligence in Finland moved from experimentation into everyday use. According to Statistics Finland, as many as 41% of people aged 16–89