
BerryMachine is a project funded by Interreg Nord, the partners being Lapland University of Applied Sciences, Natural Resources Institute Finland (LUKE) and NIBIO (Norway). The purpose of the project is to research the possibilities of artificial intelligence in detecting the amount and quality of the current berry harvest, based on a photo taken by a smartphone camera. The artificial intelligence system prototype implementation will be developed by FrostBit Software Lab.
Traditionally berry harvest sighting data is produced manually by calculating berries within one square meter forest area at a time. These sightings are later used by certain calculations to determine the overall berry harvest situation. This method is considered to take excessive amounts of time, especially during the berry counting phase. Therefore, using artificial intelligence as a tool to speed up berry counting is a potential resource saving opportunity, which would also enable others than experts to count berries easily, which would improve overall efficiency.
The phases to implement the artificial intelligence system during the project include planning and executing the acquisition of the berry photo dataset, preprocessing the berry photo dataset as well as studying, testing and implementing suitable image recognition and object detection technologies into a one complete system based on the project dataset. Creating an artificial intelligence system is a naturally iterative process, which means, earlier phases have to be re-visited if the project requires it, excluding the acquisition of the project’s photo dataset.
Preliminary technological study, Case BerryMachine
The modern artificial intelligence is an extremely wide concept, which can be divided into three different main categories, from software architecture’s point of view. These categories are traditional machine learning, deep learning and reinforced learning (Krishnan 2019). Since the BerryMachine –project focuses on image and object detection, the most natural approach is to use deep learning technologies in the project.
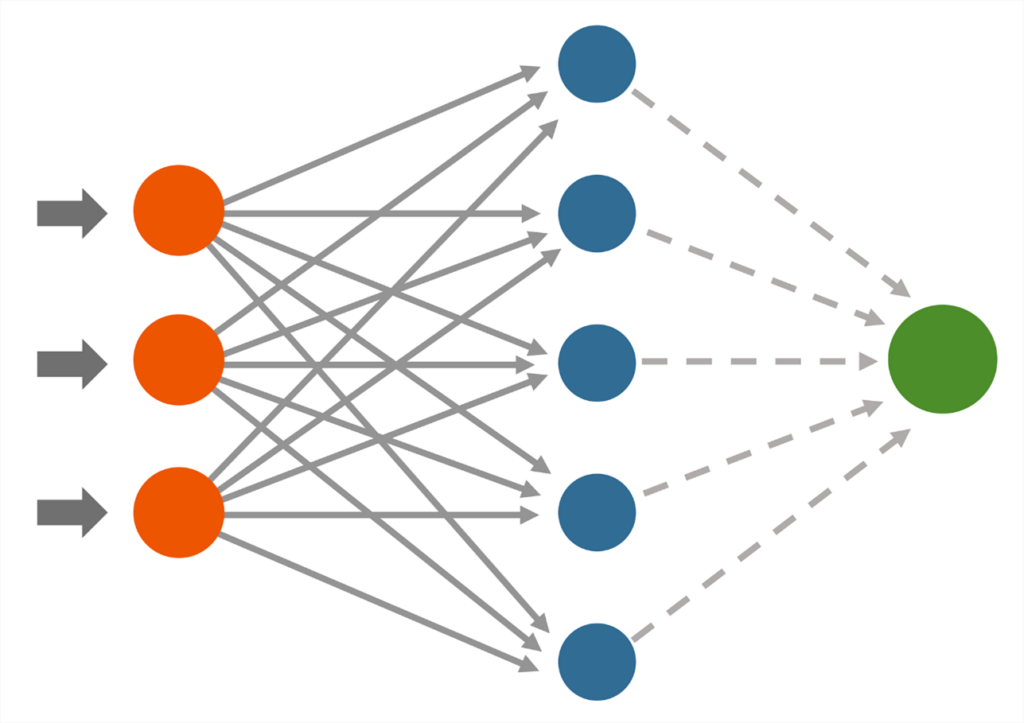
By using deep learning, the artificial intelligence learns important features that a photo consists of independently. These features can be, for example, the shape or color of the recognized object, or even the typical background where the recognized object is usually attached to (for example, a car tire is typically attached to a car). The core concept of image and object detection is a neural network, which is practically a complex and a multi-layer information processing method, which is greatly similar to the way how humans learn new things. Basically a single layer of a neural network analyzes one feature of a photo at a time. For example, one layer could focus on the object’s shape, while some other layer could analyze the object’s color (Bonner 2019; Patel 2020; Géron 2019, 448). There are multiple types of neural networks (CNN, ANN, RNN). However, in this article, we will always refer to the CNN type of neural networks, which is also known as the convolutional neural network (Pai 2020).
The theory of neural networks goes back as far as the year 1943 (McCulloch & Pitts 1943), but it hasn’t been until the last couple of decades for the modern processing power to begin being powerful enough for the needs of applying neural networks in practical applications in the field of information technology.
When it comes to image recognition, two main alternatives exist, the first being image classification and the second being object detection (Browniee 2021; Sharma 2019). Multiple approaches exist for both alternatives, and none of them is naturally better for all purposes, since it always depends on the situation. The most suitable approach and alternative that fit best the given purpose and dataset is typically found by boldly experimenting on different alternatives. (Leo 2020; Dwivedi 2020.) This is also the reason why developing image recognition systems take a considerable amount of development time. Because of this, any artificial intelligence project should have a flexible project structure to ensure the best possible outcome with the given resources.
Image classification and object detection are often used for similar purposes, however, they have different outcomes and implementations. From the outcome point of view, image classification aims to recognize what the photo depicts as a whole, while object detection aims to find every instance of the desired objects and their locations within the photo. In other words, image classification recognizes that a photo contains flowers, while object detection also points out where all the recognized flowers are located within the photo.

Common image classification technologies, neural network models and algorithms include VGG16/19, ResNet, MobileNet, Inception and Exception, just to name a few. Other viable alternatives exist also. Common object detection technologies include EfficientDet, YOLO and R-CNN. Which machine learning technology should be used in a given situation depends often on practicality related to software architecture, the compromise between detection accuracy and efficiency as well as the suitability of the technology for the project’s needs.
The practicality related to software architecture focuses on the compatibilities between technologies that only function correctly on certain software platforms and versions, which can make the software development process extremely slow and unnecessary difficult, if the compatibility issues are too frequent. The compromise between detection accuracy and efficiency refers to the process of selecting a recognition technology for the project that has the best possible accuracy detection, but it’s also light enough to be realistically used in the systems used by the project. For example, the most accurate and heaviest technologies might not be viable to be used in mobile devices, if the calculations required by the artificial intelligence is done within the mobile device itself. In the BerryMachine –project, all heavy computations are calculated on servers, which allows us to use the heavier technologies if needed. The suitability for the project’s needs refers to how well the chosen technology performs with the project’s dataset in reality. For example, some certain pre-trained image recognition model (VGG19, ResNet etc.) could perform better in recognizing vehicles in photos than some other model. (Github 2021; Hofesmann 2021; Lendave 2021; Özgenel & Sorguç 2018.)
Producing the berry photo dataset and preprocessing
The technological development of the BerryMachine –project started in spring 2021 by designing the acquisition phase of the berry photo dataset. When it comes to image recognition, the photo dataset has to be considerably large. One classic definition states that each recognizable category should have at least 1000 different photos within the dataset. On the other hand, some others imply that it can be less in some situations. The photo dataset should also be versatile, so that the artificial intelligence learns to detect the desired objects against different backgrounds as well. (Warden 2017; Huellmann 2021.) We decided to acquire a photo dataset as large and versatile as possible, so that we would surely have enough material for the project’s needs.

More than 10000 berry photos were collected during summer and autumn 2021 in the BerryMachine –project. A single observation square in this case was an aluminium frame sized one square meter, from within the berries were calculated. To process the photo dataset into the format understood by the artificial intelligence, the dataset had to be annotated first. Annotation is the process of marking down recognizable objects into each photo within the photo dataset in such a way, that the artificial intelligence can train itself to recognize the desired objects from new photos. In this case, the desired objects are raw and ripe berries as well as their flowers. The actual berry types found within the berry photo dataset are bilberry and lingonberry.
A software solution called Label Studio was used to annotate the berry photo dataset. Label Studio supports multi-user annotation process on same dataset simultaneously and also provides various different annotation data formats to be used with artificial intelligence training. Label Studio also supports using a previous self-trained machine vision model to help annotating photos automatically. In this case, the artificial intelligence finds the potential berries in the photo, and the user has to verify and fix the results, if needed.

If using traditional image classification, annotation is not needed, because the photo dataset can be processed by the artificial intelligence based on separate folders. In this case, each folder represents a single recognizable category in the image classification dataset. Since we focused on object detection in the first version of the BerryMachine artificial intelligence system, we concentrated on annotating the photo dataset in this phase.
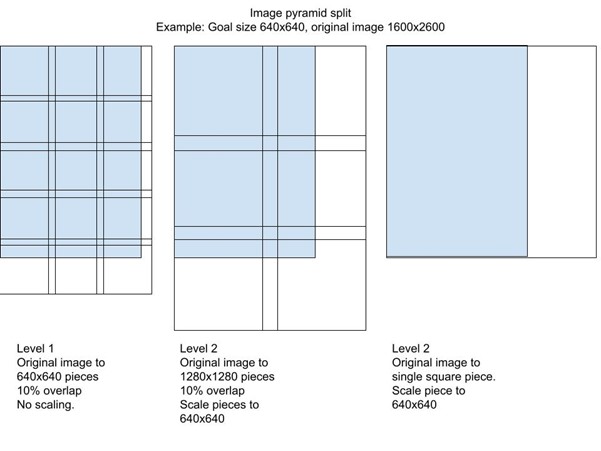
When a single photo is fed to the neural network process, the photo has to be resized into a certain size and shape. The typical image size in image classification is 224 x 224, which ensures that the photo processing time does not increase too much because of the image size. Since object detection involves mainly annotation data, we can use a greater image size by default. For example, the first version of the BerryMachine artificial intelligence system uses the YOLOv5l –object detection model, which supports photos either in the size of 640 x 640 or 1280 x 1280. The photos in the BerryMachine –photo dataset are typically larger than this, for example 2024 x 4032, which causes certain challenges in the development, since the sizes do not match with supported image sizes. If using a larger image size, it will make the training phase of the artificial intelligence considerably heavier as well.
Finally the processed photo is converted to tensor format (multidimensional matrix), which means the photo is converted to a numeric format. Since neural networks do not understand photos themselves, the numeric format is necessary so that the neural network is able to process the data. The numeric data within a tensor is often also normalized, so that each value in the data is between -1 and 1, which is optimal for training the neural network.
First technological prototype
After the photo dataset was in usable format, the next phase was to feed it to the artificial intelligence. This phase is called training the artificial intelligence, which will result in an artificial intelligence model that is able to detect those objects from a photo it has been trained to detect. In the case of BerryMachine, the artificial intelligence is trained to recognize raw and ripe berries as well as their flowers from a photo.
In order to get even the smallest photo details on board for the training phase, cropping the photo dataset was necessary. There were no ready-made automatic tools to do this cropping phase, which forced us to create our own tools. During the cropping phase, some challenges emerged, for example, berries that were in the middle of the cropping lines or close-up shots of berries that existed in multiple cropped pictures even if they were overlapping. While cropping the photo dataset automatically, the annotation data was also split simultaneously, in order to keep the dataset synchronized.
After the photo dataset was cropped and splitted and the training software of the artificial intelligence was developed, the training software and the dataset was transferred to the Mahti –supercomputer at CSC, which was launched to be used by higher education institutes in Finland in 2020 (see CSC 2020 and Docs CSC 2021).
Training an artificial intelligence often takes a considerable amount of time, and the more complex the neural network and the larger the dataset is, the longer the training time and the more processing power the training phase requires. This is the reason why graphical processors (GPU) are usually preferred over traditional processors (CPU) when training a neural network. The reason for this is the processor architecture of a GPU, which is more efficient in processing specialized calculations in parallel when compared to CPUs. This is especially useful when training neural networks (Sharabok 2020).
For the first version of the BerryMachine’s artifical intelligence system, YOLOv5l –object detection technology was chosen as the main technology. YOLOv5l was chosen mostly due the practicality and detection accuracy. YOLOv5l is programmed by using the popular PyTorch –module (Python), which makes the implementation phase far easier. YOLOv5l is also very competetive in its detection accuracy, even if compared to other common object detection technologies.
During the training phase of the artificial intelligence, the amount of available graphics card memory affects considerably the training efficiency. The Mahti –supercomputer at CSC has 40 Gb of graphics memory in total. While training the BerryMachine –artificial intelligence, even this amount of memory proved difficult, since if we tried to use the larger image size of 1280 x 1280, the memory of a single graphics card ran out. One way to solve this challenge is to revert back to the image size of 640 x 640. However, this requires a longer training phase since the photo dataset has to be cropped into smaller pieces in order to achieve the same accuracy.
In the end, it took approximately 30 hours to train the latest version of the artificial intelligence on the Mahti supercomputer. After the training phase, the next step was to evaluate the results of the training process and the detection results.
Evaluating the first results and planning for the future
The first version of the BerryMachine artificial intelligence system aimed to recognize the following categories from a given photo:
- bilberry (flower, raw, ripe)
- lingonberry (flower, raw, ripe)
- lingonberry bunch (flower, raw, ripe)
We decided to create a separate category for the lingonberry bunch. The reason for this is, based on our own experiences, it seems the artificial intelligence is more adept in recognizing a bunch than all the lingonberries separately within a bunch. This happens most likely due to the way how lingonberries grow in nature when compared, for example, to bilberries.

The detection results produced by the trained artificial intelligence system with different photos:

Evaluating an image classification and/or object detection model can be done by using a variety of tools. One of the most common tools is the so-called confusion matrix, which allows us to quickly see how well the trained artificial intelligence model is able to recognize objects correctly and incorrectly. The confusion matrix created by the first version of the BerryMachine artificial intelligence is the following:
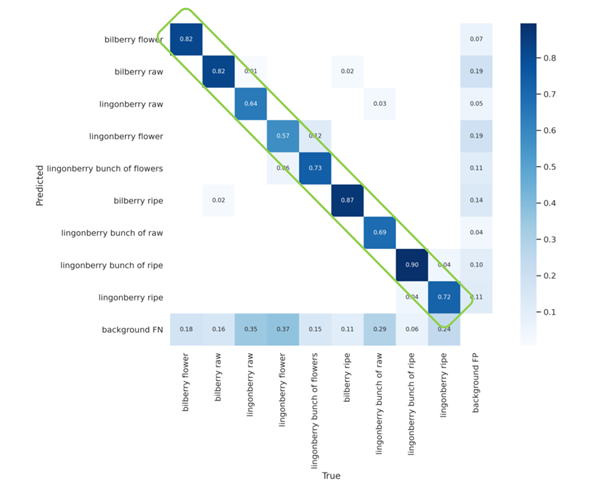
The challenges with the lingonberry detection can be seen in the figure above. The background of the photos also is problematic, especially when detecting lingonberries. Even if all of the accuracies could be greatly improved, it’s especially the lingonberry that provides most of the difficulties at the time.
The next questions therefore is: why does this happen, and what can we do to improve the artificial intelligence further? The first step is to examine the dataset itself:
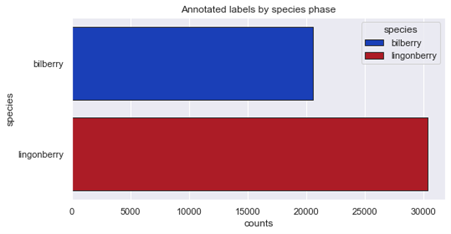
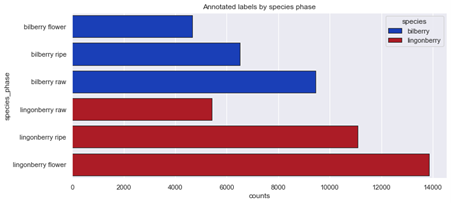
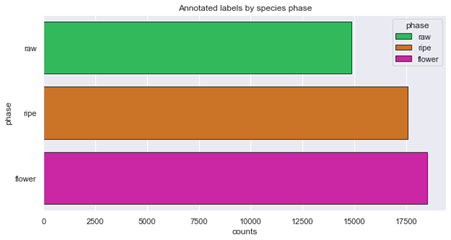
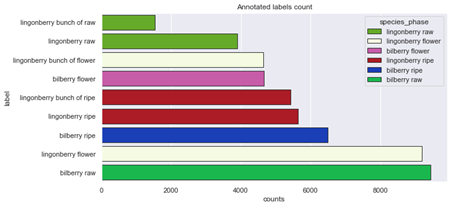
By examining the figures above, we can see the imbalances within the photo dataset. First it seems the amount of bilberry photos is too small, but if examining especially the amount of annotations, the greatest deficit is within the amount of lingonberry photos. One approach to improve the dataset would to obtain more material for this category, and then retrain the artificial intelligence again.
We can also notice the following:
- Lingonberries have more annotations than bilberries as a whole
- Amount of annotations based on ripeness level are balanced within all photos
- Amount of annotations are balanced between growing phases within a single berry type
- The amount of annotations is considerably lower in raw lingonberries and lingonberry bunches when comparing to other categories. This correlates with the other difficulties considering the detection of lingonberries (see the earlier confusion matrix), but doesn’t most likely explain all the difficulties within lingonberry detection
In addition to complementing the dataset, we can also consider other methods to improve the artificial intelligence system. These include:
- Replacing the currently used object detection technology completely
- Using a heavier object detection model, for example, YOLOv5x
- Creating more additional artificial intelligence tools to further process lingonberry detections in cases, where the artificial intelligence is not confident enough of the correct detection
- Using image classification technology to support the object detection technology
Generally it seems we are not going to achieve a satisfying detection accuracy solely relying on object detection technologies. Because of this, FrostBit is going to combine object detection with conventional image classification next, to further process problematic detection cases.
Even if we can’t provide exact numbers, we can provide an educated guess on typical detection accuracies based on different image detection technologies. Based on our own experiences, the typical detection accuracy in object detection is between 40-70%, while the typical detection accuracy in image classification is typically between 80-95% per single photo. The limitation in image classification is that they only analyze the photo as a whole, for example, whether the photo has a raw lingonberry or a ripe bilberry etc.
Since image classification can only detect what the photo depicts as a whole, it’s not effective in recognizing multiple berries from a single photo at once. Because of this, the next version of the BerryMachine –project’s artificial intelligence system will use object detection only to find berries on the general level within a photo, all of which are cropped into separate smaller photos, which will finally be processed by image classification technologies. Therefore, the general software architecture can be visualized in the following way:
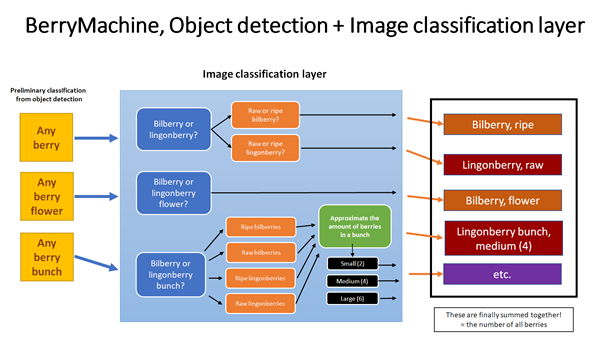
Creating any kind of artificial intelligence system can potentially take an infinite amount of development time, the only limitations being creativity and available processing power. Because of this, FrostBit aims to get as much as possible out of the artificial intelligence technologies within given resources during the project. After the BerryMachine –project, it will be interesting to see how far did we get with the developed berry detection system and what can we create next based on our previous findings. Every development iteration seems to take us closer to our original objective.
The BerryMachine –project is being funded by Interreg Nord 2014-2020. The total budget of the project is 144 431 euros, of which 122 766 euros is being funded by the EU. The project schedule is 1.1.2021 – 30.9.2022.

This article has been evaluated by the FrostBit’s publishing committee, which includes Heikki Konttaniemi, Toni Westerlund, Jarkko Piippo, Tuomas Valtanen, Pertti Rauhala and Tuuli Nivala. The article publications can be found on the FrostBit publication blog.
References
Bonner, A. 2019. The Complete Beginner’s Guide to Deep Learning: Convolutional Neural Networks and Image Classification. Towards Data Science 2.2.2019. Accessed on 17.12.2021 https://towardsdatascience.com/wtf-is-image-classification-8e78a8235acb
Browniee, J. 2021. A Gentle Introduction to Object Recognition With Deep Learning. Machine Learning Mastery 27.1.2019. Accessed on 17.12.2021 https://machinelearningmastery.com/object-recognition-with-deep-learning/
CSC 2021. Supercomputer Mahti is now available to researchers and students – Finland’s next generation computing and data management environment is complete. CSC 26.8.2020. Accessed on 17.12.2021 https://www.csc.fi/en/-/supercomputer-mahti-is-now-available-to-researchers-and-students
Docs CSC 2021. Technical details about Mahti. Docs CSC 14.4.2021. Accessed on 17.12.2021 https://docs.csc.fi/computing/systems-mahti/
Dwivedi, P. 2020. YOLOv5 compared to Faster RCNN. Who wins?. Towards Data Science 30.1.2020. Accessed on 17.2.2021 https://towardsdatascience.com/yolov5-compared-to-faster-rcnn-who-wins-a771cd6c9fb4
Géron, A. 2019. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd edition. Sebastobol: O’Reilly Media
Github.com 2021. TensorFlow 2 Detection Model Zoo. Github.com 7.5.2021. Accessed on 17.12.2021 https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md
Hofesmann, E. 2021. Guide to Conda for TensorFlow and PyTorch. Towards Data Science 11.1.2021. Accessed on 17.12.2021
https://towardsdatascience.com/guide-to-conda-for-tensorflow-and-pytorch-db69585e32b8
Huellmann, T. 2021. How to build a dataset for image classification. Levity 9.11.2021. Accessed on 17.12.2021 https://levity.ai/blog/create-image-classification-dataset
Krishnan, B. P. 2019. Machine learning Vs Deep learning Vs Reinforcement learning. Medium 18.9.2019. Accessed on 16.12.2021 https://medium.com/analytics-vidhya/machinelearning-deeplearning-reinforcementlearning-ed7b217861c5
Lendave, V. 2021. A Comparison of 4 Popular Transfer Learning Models. Analytics India Magazine 1.9.2021. Accessed on 17.12.2021 https://analyticsindiamag.com/a-comparison-of-4-popular-transfer-learning-models/
Leo, M. S. 2020. How to Choose the Best Keras Pre-Trained Model for Image Classification. Towards Data Science 15.11.2020. Accessed on 17.12.2021 https://towardsdatascience.com/how-to-choose-the-best-keras-pre-trained-model-for-image-classification-b850ca4428d4
McCulloch, W.S. & Pitts, W. 1943. A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics 5, 1943, 115–133. https://doi.org/10.1007/BF02478259
Pai, A. 2020. CNN vs. RNN vs. ANN – Analyzing 3 Types of Neural Networks in Deep Learning. Analytics Vidhya 17.2.2020. Accessed on 17.12.2021 https://www.analyticsvidhya.com/blog/2020/02/cnn-vs-rnn-vs-mlp-analyzing-3-types-of-neural-networks-in-deep-learning/
Patel, K. 2020. Image Feature Extraction: Traditional and Deep Learning Techniques. Towards Data Science 9.9.2020. Accessed on 17.12.2021 https://towardsdatascience.com/image-feature-extraction-traditional-and-deep-learning-techniques-ccc059195d04
Sharabok, G. 2020. Why Deep Learning Uses GPUs? Towards Data Science 26.7.2020. Accessed on 17.12.2021 https://towardsdatascience.com/why-deep-learning-uses-gpus-c61b399e93a0
Sharma, P. 2019. Image Classification vs. Object Detection vs. Image Segmentation. Analytics Vidhya 21.8.2019. Accessed on 17.12.2021 https://medium.com/analytics-vidhya/image-classification-vs-object-detection-vs-image-segmentation-f36db85fe81
Warden, P. 2017. How many images do you need to train a neural network? Pete Warden’s Blog 14.12.2017. Accessed on 17.12.2021 https://petewarden.com/2017/12/14/how-many-images-do-you-need-to-train-a-neural-network/
Özgenel, Ç.F. & Sorguç, A. G. 2018. Performance Comparison of Pretrained Convolutional Neural Networks on Crack Detection in Buildings. Berlin. 35th International Symposium on Automation and Robotics in Construction (ISARC 2018). Accessed on 17.12.2021 https://www.iaarc.org/publications/fulltext/ISARC2018-Paper154.pdf

Mikko Pajula
Mikko is a coder and part time teacher. His programming tasks are mainly full-stack development with extra knowlegde in GIS and deep learning.

Tuomas Valtanen
Tuomas works as the web/mobile team leader, a software engineer and a part-time teacher in FrostBit at Lapland UAS. His tasks include project management, project planning as well as software engineering and expertise in web, mobile and AI applications.