Marjamasiina (eng. BerryMachine) on Interreg Nordin rahoittama hanke, jonka osapuolina toimivat Lapin ammattikorkeakoulu, FrostBit Software Lab, Luonnonvarakeskus (LUKE) sekä NIBIO (Norja). Hankkeen tarkoituksena on tutkia tekoälyn hyödyntämisen mahdollisuutta marjasadon määrän sekä laadun arvioimisessa älypuhelimella otetun valokuvan perusteella. Hankkeen tekoälyjärjestelmän prototypoinnista ja toteutuksesta vastaa FrostBit ohjelmistolaboratorio.
Perinteisesti marjasatohavaintoja tuotetaan maastossa käsin laskemalla yhden neliömetrin alueelta kerrallaan. Näistä havainnoista tuotetaan marjasadon yleistilanne tiettyjen laskelmien pohjalta. Tämän menetelmän on todettu vievän paljon aikaa erityisesti marjojen laskentavaiheessa, minkä vuoksi tekoälyn valjastaminen laskentatyöhön on potentiaalisesti resursseja säästävä mahdollisuus, jonka avulla olisi helppoa osallistaa muitakin laskentatyöhön perehtymättömiä henkilöitä mukaan toiminnan tehostamiseksi. Projektin tekoälyjärjestelmän toteuttamisen eri vaiheet koostuvat aineiston keräämisen suunnittelusta ja toteuttamisesta, aineiston esikäsittelystä sekä soveltuvien kuvan- ja objektintunnistustekniikoiden selvittämisestä, testaamisesta ja implementoinnista projektin kuva-aineiston pohjalta yhteen kokonaiseen järjestelmään. Tekoälyjärjestelmän kehittäminen on luonnostaan iteratiivinen prosessi, mikä tarkoittaa sitä, että aiempiin työvaiheisiin palataan tarvittaessa montakin kertaa projektin aikana aineiston keräämistä lukuun ottamatta.
Tekninen esiselvitys, Case Marjamasiina
Moderni tekoäly on erittäin laaja käsite, joka voidaan ohjelmistoarkkitehtuurin näkökulmasta jakaa karkealla tasolla kolmeen pääkategoriaan. Näitä kategorioita ovat perinteinen koneoppiminen, syväoppiminen sekä vahvistettu oppiminen (Krishnan 2019). Koska Marjamasiina-hanke keskittyy kuvien ja objektien tunnistamiseen valokuvasta, luonnollisin lähestymistapa ongelmaan on hyödyntää syväoppimista.
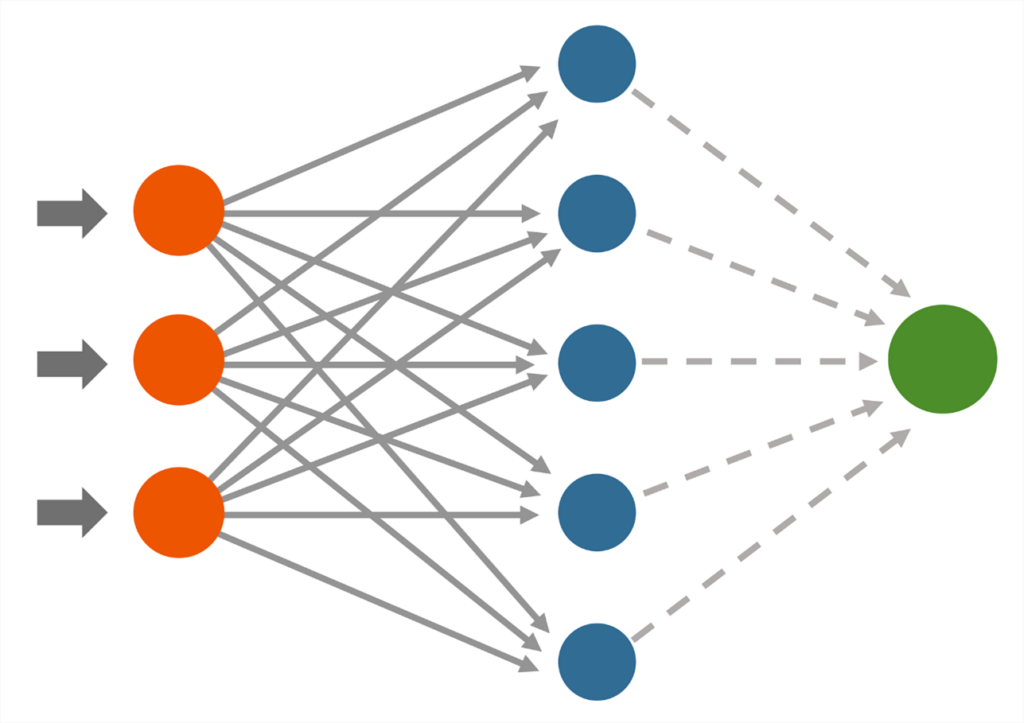
Syväoppimisen avulla tekoäly oppii kuva-aineistosta itsenäisesti tärkeitä ominaisuuksia, joista yksittäinen valokuva koostuu. Näitä ominaisuuksia voivat olla esimerkiksi tunnistettavan objektin muoto, väri tai vaikka jokin toinen objekti, johon tunnistettava objekti on tyypillisesti kiinnitetty (esimerkiksi auton rengas, joka on usein kiinni autossa). Kuvan- ja objektintunnistuksen ytimenä toimii neuroverkko, joka on käytännössä monimutkainen ja -tasoinen tiedon prosessointimenetelmä, joka muistuttaa suuresti tapaa, jolla myös ihmiset oppivat asioita. Käytännössä yksittäinen neuroverkon taso tutkii valokuvasta aina yhtä ominaisuutta kerrallaan, esimerkiksi jonkin asian muotoa, kun taas toinen taso voisi tutkia esimerkiksi väriä. (Bonner 2019; Patel 2020; Géron 2019, 448.) Neuroverkkoja on olemassa useita eri tyyppejä (CNN, ANN, RNN), mutta tässä artikkelissa viittaamme aina CNN-neuroverkkoon, eli konvolutionaaliseen neuroverkkoon (Pai 2020).
Neuroverkkojen teoria juontaa juurensa vuoteen 1943 (McCulloch & Pitts 1943), mutta vasta viime vuosikymmenten aikana tietokoneiden teho on saatu sellaiselle tasolle, jotta neuroverkkoja voidaan realististesti hyödyntää erilaisissa tietotekniikan sovelluksissa.
Kuvantunnistuksessa sen sijaan on pääsääntöisesti kaksi eri lähestymistapaa, joita ovat kuvien luokittelu (image classification) sekä objektien tunnistaminen (object detection) (Browniee 2021; Sharma 2019). Molempien lähestymistapojen toteuttamiseen on lukuisia eri vaihtoehtoja, joista yksikään ei ole ylitse muiden, vaan sopivin valinta on aina tapauskohtainen. Lähestymistapa ja vaihtoehto, jotka sopivat käyttötarkoitukseen ja aineistoon, selviää parhaiten usein vain rohkeasti kokeilemalla. (Leo 2020; Dwivedi 2020.) Tämän vuoksi kuvantunnistusjärjestelmien luominen vie usein huomattavasti kehitysaikaa, minkä vuoksi tekoälyprojektissa tulee olla joustava rakenne mahdollisimman hyvän lopputuloksen saavuttamiseksi.
Kuvanluokittelun ja objektintunnistuksen käyttötarkoitus on usein hyvin samankaltainen, mutta ne eroavat kuitenkin lopputuloksen sekä toteutustavan näkökulmasta. Lopputuloksen näkökulmasta kuvanluokittelu pyrkii analysoimaan kuvaa kokonaisuutena sekä löytämään tiedon siitä, mitä kuva esittää kokonaisuudessaan. Objektintunnistus taas pyrkii löytämään jokaisen etsittävän asian kuvassa, ja näyttämään niiden tarkan sijainnin kuvan sisällä. Toisin sanoen, kuvanluokittelu tunnistaa, että valokuvassa näkyy kukkia, mutta objektintunnistus voi myös näyttää missä kohdin kuvaa kaikki kuvan kukat sijaitsevat.

Yleisiä teknologioita, neuroverkkomalleja ja algoritmejä, joita voidaan hyödyntää kuvanluokittelussa, ovat mm. VGG16/19, ResNet, MobileNet, Inception ja Exception. Lukuisia muitakin varteenotettavia vaihtoehtoja on. Objektintunnistuksessa yleisiä teknologioita sen sijaan ovat EfficientDet, YOLO sekä R-CNN. Mitä koneoppimisen tekniikkaa kannattaa käyttää missäkin tilanteessa, riippuu usein ohjelmistoarkkitehtuurin käytännöllisyydestä, tunnistustarkkuuden ja -tehokkuuden välisestä kompromissista sekä soveltuvuudesta itse projektin käyttötarkoitukseen.
Ohjelmistoarkkitehtuurin käytännöllisyydellä tarkoitetaan sitä, että tietty teknologia tai algoritmi ei välttämättä toimi kuin juuri tietyillä sovellusalustoilla ja -versioilla, mikä saattaa tehdä kehitystyöstä todella hidasta ja vaikeaa mikäli yhteensopivuusongelmia on liikaa. Tarkkuuden ja tehokkuuden välisellä kompromissilla tarkoitetaan sitä, että tekoälyn toteutusta varten pyritään valitsemaan sellainen teknologia taustalle, joka on mahdollisimman tarkka tunnistamaan asioita, mutta sitä silti voidaan realistisesti käyttää siinä kontekstissa mihin se on suunniteltu. Esimerkiksi kaikkein raskaimpia ja tarkimpia tekniikoita ei välttämättä voida käyttää mobiililaitteissa, jos tekoälyn vaatima laskenta suoritetaan itse mobiililaitteessa. Marjamasiina-hankkeessa kaikki raskas laskenta suoritetaan palvelimilla, jolloin voimme käyttää myös raskaampia teknologioita. Soveltuvuudella käyttötarkoitukseen tarkoitetaan sitä, että kuinka hyvin valittu teknologia toimii annetulla aineistolla. Esimerkiksi jokin esikoulutettu konenäkömalli (VGG19, ResNet jne.) voi soveltua paremmin vaikkapa ajoneuvojen tunnistamiseen kuin jokin toinen. (Github 2021; Hofesmann 2021; Lendave 2021; Özgenel & Sorguç 2018.)
Marjakuva-aineiston tuottaminen ja esikäsittely
Marjamasiina-hankkeen tekninen toteutus alkoi aineiston keräämisen suunnittelulla keväällä 2021. Kuvantunnistuksen näkökulmasta aineistoa pitää olla runsaasti, ja eräs klassinen määritelmä onkin, että jokaista tunnistettavaa asiaa eli kategoriaa kohden pitää olla vähintään 1000 eri valokuvaa aineistossa. Toisaalta osa taas on sitä mieltä, että vähempikin riittää ja tarvittava kuvien määrä on tapauskohtainen. Myös kuva-aineiston monipuolisuus on erittäin tärkeää, jotta tekoäly oppii tunnistamaan haluttuja asioita myös erilaisia taustoja vasten. (Warden 2017; Huellmann 2021.) Päätimme kuitenkin Marjamasiina –hankkeessa kerätä mahdollisimman suuren ja monipuolisen aineiston, jotta kuvamateriaalia on varmasti käytettävissä tarpeeksi, oli tilanne mikä tahansa.

Marjamasiina-hankkeessa kerättiin kesän ja alkusyksyn 2021 aikana yli 10000 valokuvaa eri marjaruudukoista. Yksittäinen marjaruudukko tässä tapauksessa on neliömetrin kokoinen alumiinikehikko, jonka sisältä marjojen lukumäärä lasketaan. Jotta kuva-aineisto saatiin tekoälylle käyttökelpoiseen muotoon objektintunnistusta varten, piti se ensin annotoida. Annotointi tarkoittaa tunnistettavien objektien merkitsemistä käsin kuva-aineistoon siten, että tekoäly kykenee kouluttamaan itsensä tunnistamaan sovittuja objekteja uusista valokuvista. Tässä tapauksessa tunnistettavia objekteja ovat raa’at ja kypsät marjat sekä marjojen kukat. Varsinaisista marjoista aineistossa ovat edustettuna mustikka ja puolukka.
Aineiston annotoinnissa hyödynnettiin Label Studio –ohjelmistoa, joka tukee monen henkilön työskentelyä saman kuva-aineiston parissa tehokkaasti sekä tarjoaa useita eri annotointidataformaatteja tekoälyn kouluttamista varten. Label Studio tukee myös viimeisimmän itse koulutetun konenäkömallin käyttämistä automaattiannotoinnissa. Tällöin tekoäly etsii potentiaaliset marjat ja käyttäjälle jää tehtäväksi tarkistaa ja korjata annotaatiot.

Tavanomaisessa kuvanluokittelussa ei sen sijaan tarvita annotointia, vaan kuvat voidaan syöttää kansioittain tekoälylle, jolloin jokainen tunnistettava asia (kategoria) syötetään tekoälylle omassa alikansiossaan. Koska keskityimme Marjamasiinan ensimmäisessä versiossa objektintunnistukseen kuvanluokittelun sijaan, keskityimme tässä vaiheessa vain aineiston annotointiin.
Kun yksittäinen valokuva syötetään tekoälyn neuroverkon prosessoitavaksi, pitää se muuttaa tiettyyn kokoon sekä muotoon. Kuvanluokittelussa tyypillinen kuvakoko on 224 x 224, jolla taataan se, ettei prosessointi muutu kuvien koon vuoksi liian raskaaksi. Koska objektintunnistuksessa prosessoidaan lähinnä annotointidataa, voidaan käyttää suurempaa kuvakokoa. Esim. Marjamasiinan tekoälyjärjestelmän ensimmäisessä versiossa käytössä oleva YOLOv5l-objektintunnistusmalli tukee 640 x 640 ja 1280 x 1280 –pikselin kokoisia kuvia. Marjamasiina-hankkeen kuva-aineiston kuvat ovat usein tätä suurempia, esim. 2024 x 4032 pikseliä, mikä tuo tiettyjä haasteita toteutukseen, koska se ei täsmää tuettuihin kuvakokoihin. Suurempaa kuvakokoa hyödyntävä neuroverkko myös tekee tekoälyn koulutusvaiheesta raskaamman.
Lopulta kuva muutetaan tensorimuotoon (moniulotteinen matriisi) eli numeroiksi, jotta neuroverkko kykenee prosessoimaan dataa. Neuroverkot eivät itsessään ymmärrä kuvia, vaan ainoastaan numeerista dataa, minkä vuoksi tämä datamuunnos on välttämätön. Tensorissa oleva numeerinen data usein myös normalisoidaan, jotta jokainen arvo saadaan esitettyä välillä -1 ja 1, mikä on optimaalisin datamuoto neuroverkon kouluttamisen näkökulmasta.
Ensimmäinen tekninen prototyyppi
Kun kuva-aineisto oli sopivassa muodossa, siirrettiin se tekoälyn hyödynnettäväksi. Käytännössä tällöin puhutaan tekoälyn kouluttamisesta, jonka lopputuloksena syntyy tekoälymalli, joka kykenee tunnistamaan valokuvista niitä asioita, joita se on koulutettu tunnistamaan. Marjamasiinan tapauksessa tekoäly koulutetaan tunnistamaan valokuvista kypsiä ja raakoja marjoja sekä niiden kukkia.
Jotta tekoälyn kouluttamiseen saadaan kuvista myös pienimmät yksityiskohdat mukaan, kuvien pilkkominen osiin oli Marjamasiinan kuva-aineiston osalta tarpeen. Pilkkomista varten ei ollut suoraan mitään valmista automaattista työkalua, joten sellainen piti toteuttaa itse. Kuvien pilkkomisessa tuli nopeasti vastaan ongelmia, kuten vaikkapa marjat, jotka olivat leikkauskohtien keskellä tai lähikuvat marjoista, jotka ulottuivat useamman leikatun kuvan alueelle päällekkäisyydestä huolimatta. Samalla kun kuva-aineistoa pilkottiin koneellisesti, pilkottiin samalla myös jokaiseen kuvaan liitetty annotointidata, jotta aineisto pysyi synkronisoituna tekoälyn kouluttamista varten.
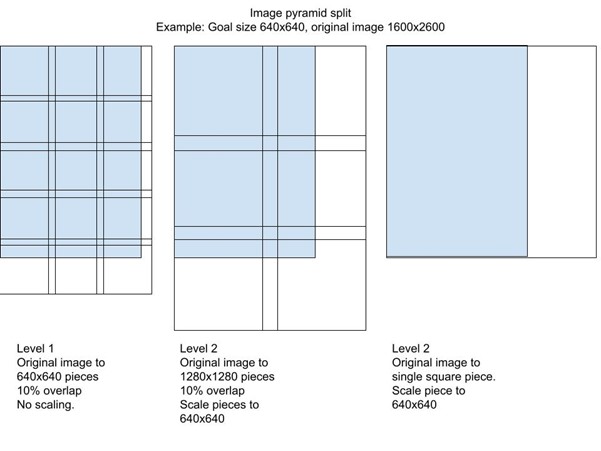
Kun kuva-aineisto oli pilkottu ja tekoälyn koulutusohjelmisto ohjelmoitu, asennettiin hankkeessa tuotettu tekoälyn koulutusohjelmisto kuva-aineistoineen CSC:n Mahti-supertietokoneelle, joka avattiin korkeakoulujen käytettäväksi vuonna 2020. (ks. CSC 2020 ja Docs CSC 2021.)
Tekoälyn kouluttaminen vie usein runsaasti aikaa, ja mitä monimutkaisempi neuroverkko ja laajempi aineisto on koulutettavana, sen enemmän aikaa koulutus vie ja sitä enemmän koulutusprosessi vaatii laskentatehoa. Tämän vuoksi tekoälyn kouluttamisessa käytetään tyypillisesti tavanomaisen tietokoneen suorittimen (CPU) sijaan näytönohjaimen suoritinta (GPU). Tämä johtuu siitä, että näytönohjaimen prosessoriarkkitehtuuri soveltuu tavanomaista prosessoria tehokkaammin erikoisempien laskutoimitusten suorittamiseen samanaikaisesti, mikä taas palvelee erityisen hyvin tekoälyn koulutusta silloin, kun käytössä on neuroverkko (Sharabok 2020).
Marjamasiinan tekoälyjärjestelmän ensimmäisessä versiossa valittiin käytettäväksi YOLOv5l –objektintunnistustekniikka. YOLOv5l valikoitui hankkeen objektintunnistustekniikaksi lähinnä käytettävyyden sekä tunnistustehokkuuden vuoksi. YOLOv5l:ää voidaan käyttää suositun PyTorch –moduulin (Python) avulla, mikä tekee toteutusvaiheesta helpomman. YOLOv5l on erittäin kilpailukykyinen vaihtoehto myös tunnistustarkkuuden näkökulmasta verrattuna muihin yleisiin objektintunnistustekniikoihin.
Tekoälyn koulutuksessa myös näytönohjaimen muistikoko vaikuttaa oleellisesti tehokkuuteen. CSC:n Mahti-supertietokoneella on kaikkiaan käytössään 40Gb eri näytönohjainmuisteja. Huomasimme Marjamasiinan tekoälyn koulutuksen aikana jopa tämän muistimäärän ongelmallisuudet, sillä jos kokeilimme tehdä koulutusta suuremmalla 1280 x 1280 –pikselin kuvakoolla, loppui yksittäisen näytönohjaimen muisti kesken. Yksi tapa vaikuttaa tähän on käyttää 640 x 640 –pikselin kokoluokkaa koulutuksessa, mutta se vaatii pitemmän koulutusajan koska aineisto pitää pilkkoa pienempiin osiin, jotta samaan tarkkuuteen voidaan päästä.
Loppujen lopuksi Marjamasiinan tekoälyjärjestelmän viimeisimmän version kouluttaminen vei Mahti-supertietokoneelta kaiken kaikkiaan n. 30 tuntia. Tekoälyn kouluttamisen jälkeen vuorossa oli koulutusprosessin sekä tulosten arviointi.
Ensimmäisten tulosten arviointi sekä suunnitelmat tulevaisuuden varalle
Marjamasiinan tekoälyjärjestelmän ensimmäinen versio pyrkii tunnistamaan annetusta valokuvasta seuraavia kategorioita:
- mustikka (kukka, raaka, kypsä)
- puolukka (kukka, raaka, kypsä)
- puolukkaterttu (kukka, raaka, kypsä)
Päädyimme luomaan puolukkatertuille oman kategorian, koska kokemuksemme mukaan vaikutti siltä, että tekoälyn on helpompi tunnistaa kokonainen puolukkaterttu kuin kaikki tertun puolukat erikseen. Tämä johtuu lähinnä siitä, millä tavalla puolukat ylipäätänsä kasvavat verrattuna vaikkapa mustikkaan.

Koulutetun tekoälyjärjestelmän tunnistustuloksia käytännössä eri kuvilla:

Kuvan- ja objektintunnistuksen mallin arvioinnissa käytetään useita eri työkaluja, joista yksi yleisimmistä on ns. sekaannusmatriisi, josta näkee nopeasti, kuinka tekoälymalli tunnistaa objekteja oikein ja väärin prosentuaalisesti. Ensimmäisen version tuottama tekoälymalli tuotti seuraavanlaisen sekaannusmatriisin:
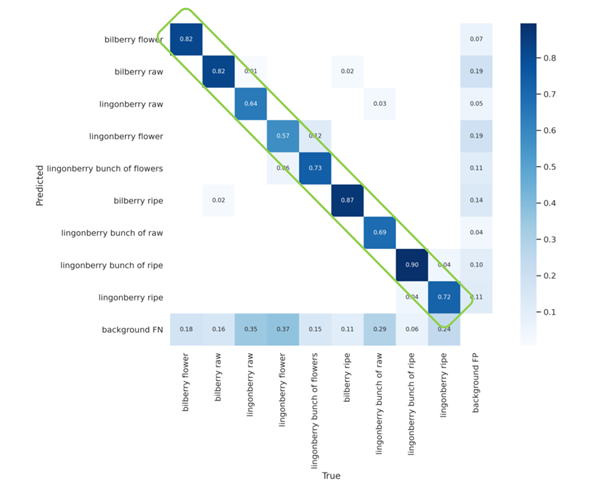
Ylläolevasta kuvasta näkee puolukoiden tunnistamisessa esiintyvät haasteet. Myös kuvien tausta aiheuttaa ongelmia erityisesti puolukoiden osalta. Vaikka tarkkuudessa on kauttaaltaan vielä parannettavaa, erityisesti puolukat ovat tällä hetkellä ongelmallinen marjalajike tunnistuksen näkökulmasta.
Seuraava kysymys onkin: mistä kaikki tämä johtuu ja miten voimme kehittää tekoälymallia entisestään? Ensimmäinen vaihe on tutkia itse aineistoa:
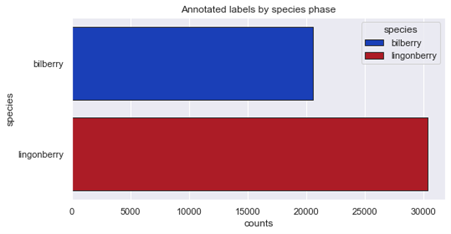
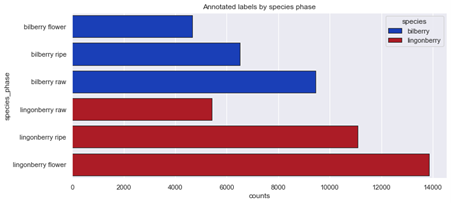
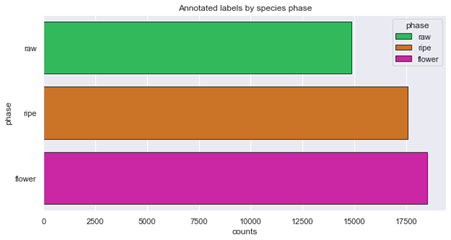
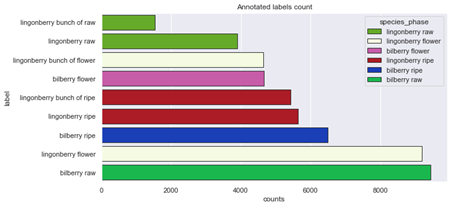
Ylläolevista kuvista voidaan huomata kuva-aineistossa esiintyviä epätasapainoja. Aluksi vaikuttaa siltä, että mustikoiden kuvia on liian vähän, mutta erityisesti annotointien näkökulmasta suurin vaje on raakojen puolukoiden kuvissa. Yksi lähestymistapa on täydentää aineistoa juuri tällä kategorialla, ja kokeilla kouluttaa tekoälymalli uudestaan.
Lisäksi voidaan todeta seuraavaa:
- Puolukoita on annotoitu kokonaisuutena enemmän kuin mustikoita
- Kypsyysasteittain annotointien määrä on tasapainossa kaikkien kuvien osalta
- Kasvuvaiheittain annotointien määrä on tasapainossa suhteessa kyseisen marjan annotointien kanssa
Erityisesti raakojen puolukoiden ja varsinkin raakojen puolukkaterttujen määrä annotoidussa aineistossa on huomattavan paljon pienempi verrattuna muihin kategorioihin. Tämä korreloi puolukan tunnistamisen ongelmien kanssa (ks. aiempi sekaannusmatriisi), mutta tuskin selittää kokonaisuudessaan puolukoiden tunnistamisen ongelmia
Aineiston täydentämisen lisäksi voimme harkita myös muita tapoja kehittää tekoälyjärjestelmää. Näitä ovat:
- Käytettävän objektintunnistusteknologian vaihtaminen kokonaan
- Raskaamman objektintunnistusmallin hyödyntäminen, kuten YOLOv5x
- Kehittämällä lisää tekoälyä hyödyntäviä aputyökaluja, jotka voivat jatkojalostaa puolukoiden tunnistamista niissä tapauksissa, joissa tekoäly ei ole täysin varma tunnistuksen oikeellisuudesta
- Kuvanluokittelutekoälyn hyödyntäminen objektintunnistuksen tukena
Kokonaisuutena vaikuttaa suuresti siltä, että pelkkä objektintunnistus ei riitä tarvittavaan tarkkuuteen marjojen tunnistamisessa. Tämän vuoksi FrostBit aikoo seuraavaksi yhdistää objektintunnistuksen tavanomaiseen kuvanluokitteluun, jotta voimme tutkia tarkemmin objektintunnistusjärjestelmän löytämiä ongelmatapauksia.
Vaikka mitään varmoja lukuja emme voi esittää, voimme varovasti arvioida eri teknologioiden tyypillisiä tunnistamistarkkuuksia. Omien kokemustemme mukaan objektintunnistamisessa tyypillinen keskimääräinen tunnistustarkkuus liikkuu 40–70 % välillä, kun taas tavanomaisella kuvanluokittelulla päästään usein 80–95 % tarkkuuteen yksittäisen kuvan osalta. Kuvanluokittelun rajoitus on se, että se analysoi ainoastaan kokonaista kuvaa, eli onko kuvassa esim. raaka puolukka vai kypsä mustikka.
Koska kuvanluokittelu ei voi tunnistaa muuta kuin sen mitä kuva esittää kokonaisuudessaan, se ei yksinään kykene tunnistamaan tehokkaasti useita eri marjoja samasta kuvasta. Tämän vuoksi seuraava Marjamasiina-hankkeen tekoälyjärjestelmän versio tulee hyödyntämään objektintunnistusta ainoastaan marjojen etsimiseen, joista pilkotaan jokainen marja erikseen kuvana, joista jokainen syötetään kuvanluokitustekoälylle jatkokäsittelyyn. Kokonaisarkkitehtuuria voidaan tällöin kuvata seuraavalla tavalla:
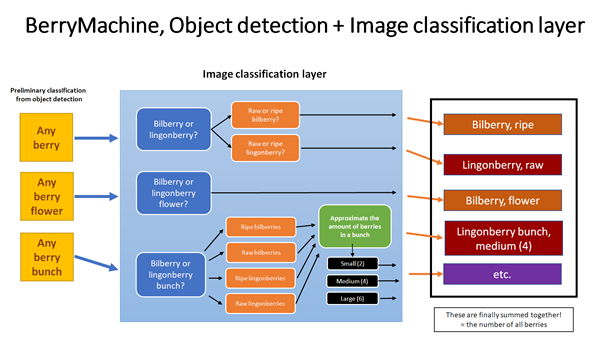
Tekoälyn kehittämiseen voisi käytännössä käyttää loputtomiin aikaa, sillä vain luovuus ja saatavilla oleva laskentateho ovat rajana. Tämän vuoksi FrostBit pyrkii saamaan tekoälystä mahdollisimman paljon irti annettujen resurssien puitteissa hankkeen aikana. Marjamasiina-hankkeen päätyttyä onkin mielenkiintoista nähdä kuinka pitkälle marjantunnistusteknologian osalta pääsimme, ja mitä sen pohjalta voimme seuraavaksi alkaa rakentamaan. Jokainen iteraatio tuntuu vievän meitä lähemmäs alkuperäistä tavoitetta.
Marjamasiina-hanke on Interreg Nord 2014-2020:n rahoittama hanke, jonka kokonaiskustannukset ovat 144 431 euroa, josta EU-rahoitusosuus on 122 766 euroa. Hankkeen toteutusaika on 1.1.2021 – 30.9.2022.

Lähteet
Bonner, A. 2019. The Complete Beginner’s Guide to Deep Learning: Convolutional Neural Networks and Image Classification. Towards Data Science 2.2.2019. Accessed on 17.12.2021 https://towardsdatascience.com/wtf-is-image-classification-8e78a8235acb
Browniee, J. 2021. A Gentle Introduction to Object Recognition With Deep Learning. Machine Learning Mastery 27.1.2019. Accessed on 17.12.2021 https://machinelearningmastery.com/object-recognition-with-deep-learning/
CSC 2021. Supercomputer Mahti is now available to researchers and students – Finland’s next generation computing and data management environment is complete. CSC 26.8.2020. Accessed on 17.12.2021 https://www.csc.fi/en/-/supercomputer-mahti-is-now-available-to-researchers-and-students
Docs CSC 2021. Technical details about Mahti. Docs CSC 14.4.2021. Accessed on 17.12.2021 https://docs.csc.fi/computing/systems-mahti/
Dwivedi, P. 2020. YOLOv5 compared to Faster RCNN. Who wins?. Towards Data Science 30.1.2020. Accessed on 17.2.2021 https://towardsdatascience.com/yolov5-compared-to-faster-rcnn-who-wins-a771cd6c9fb4
Géron, A. 2019. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. 2nd edition. Sebastobol: O’Reilly Media
Github.com 2021. TensorFlow 2 Detection Model Zoo. Github.com 7.5.2021. Accessed on 17.12.2021 https://github.com/tensorflow/…/tf2_detection_zoo.md
Hofesmann, E. 2021. Guide to Conda for TensorFlow and PyTorch. Towards Data Science 11.1.2021. Accessed on 17.12.2021
https://towardsdatascience.com/guide-to-conda-for-tensorflow-and-pytorch-db69585e32b8
Huellmann, T. 2021. How to build a dataset for image classification. Levity 9.11.2021. Accessed on 17.12.2021 https://levity.ai/blog/create-image-classification-dataset
Krishnan, B. P. 2019. Machine learning Vs Deep learning Vs Reinforcement learning. Medium 18.9.2019. Accessed on 16.12.2021 https://medium.com/analytics-vidhya/machinelearning-deeplearning-reinforcementlearning-ed7b217861c5
Lendave, V. 2021. A Comparison of 4 Popular Transfer Learning Models. Analytics India Magazine 1.9.2021. Accessed on 17.12.2021 https://analyticsindiamag.com/a-comparison-of-4-popular-transfer-learning-models/
Leo, M. S. 2020. How to Choose the Best Keras Pre-Trained Model for Image Classification. Towards Data Science 15.11.2020. Accessed on 17.12.2021 https://towardsdatascience.com/how-to-choose-the-best-keras-pre-trained-model-for-image-classification-b850ca4428d4
McCulloch, W.S. & Pitts, W. 1943. A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics 5, 1943, 115–133. https://doi.org/10.1007/BF02478259
Pai, A. 2020. CNN vs. RNN vs. ANN – Analyzing 3 Types of Neural Networks in Deep Learning. Analytics Vidhya 17.2.2020. Accessed on 17.12.2021 https://www.analyticsvidhya.com/blog/2020/02/cnn-vs-rnn-vs-mlp-analyzing-3-types-of-neural-networks-in-deep-learning/
Patel, K. 2020. Image Feature Extraction: Traditional and Deep Learning Techniques. Towards Data Science 9.9.2020. Accessed on 17.12.2021 https://towardsdatascience.com/image-feature-extraction-traditional-and-deep-learning-techniques-ccc059195d04
Sharabok, G. 2020. Why Deep Learning Uses GPUs? Towards Data Science 26.7.2020. Accessed on 17.12.2021 https://towardsdatascience.com/why-deep-learning-uses-gpus-c61b399e93a0
Sharma, P. 2019. Image Classification vs. Object Detection vs. Image Segmentation. Analytics Vidhya 21.8.2019. Accessed on 17.12.2021 https://medium.com/analytics-vidhya/image-classification-vs-object-detection-vs-image-segmentation-f36db85fe81
Warden, P. 2017. How many images do you need to train a neural network? Pete Warden’s Blog 14.12.2017. Accessed on 17.12.2021 https://petewarden.com/2017/12/14/how-many-images-do-you-need-to-train-a-neural-network/
Özgenel, Ç.F. & Sorguç, A. G. 2018. Performance Comparison of Pretrained Convolutional Neural Networks on Crack Detection in Buildings. Berlin. 35th International Symposium on Automation and Robotics in Construction (ISARC 2018). Accessed on 17.12.2021 https://www.iaarc.org/publications/fulltext/ISARC2018-Paper154.pdf
Artikkelijulkaisut ovat FrostBitin asiantuntijakirjoituksia Lapin ammattikorkeakoulun projektien toiminnasta ja tuloksista sekä muita TKI-toimintaa ja ICT-alaa koskevista aiheista. Artikkelit arvioi FrostBitin julkaisutoimikunta.